
Large Language Models (LLMs) like GPT-4, Claude, and others have transformed how we interact with AI, enabling applications such as chatbots, content generation, and data analysis. However, to fully harness their capabilities, it’s essential to understand and implement effective chunking strategies. Chunking refers to breaking down large pieces of text or data into smaller, manageable segments, ensuring optimal performance and accuracy in LLM applications.
In this comprehensive guide, we’ll explore what chunking is, why it’s important, how to choose the right strategy, and how GlobalNodes can help you implement these techniques to enhance your AI-driven solutions.
What is Chunking Strategy for LLM Application
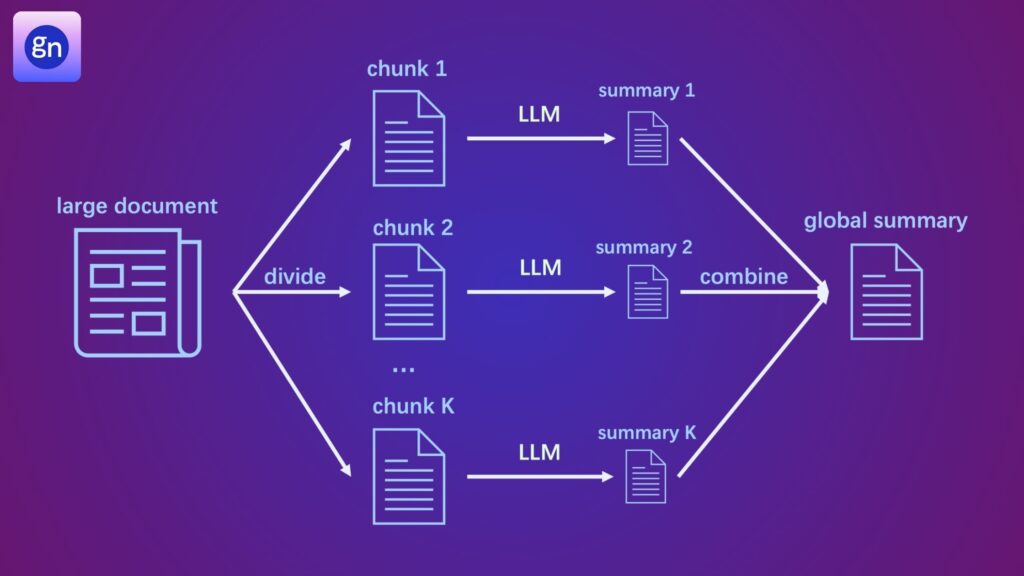
The chunking strategy in LLM (Large Language Model) applications involves breaking down large volumes of text into smaller, manageable segments or “chunks” to optimize data processing and improve model performance. This approach enhances the model’s ability to understand context, maintain coherence, and generate more accurate responses. Chunking is particularly useful in applications like document summarization, content generation, and conversational AI, where processing lengthy text at once can compromise accuracy. By dividing data into smaller parts, LLMs can process each chunk independently while retaining contextual relevance through overlapping segments or metadata. This strategy not only boosts the model’s efficiency but also reduces computational complexity, making it ideal for applications requiring high-speed, scalable AI solutions. Implementing chunking ensures more precise and contextually aware outputs, especially for enterprise applications dealing with extensive data volumes.
Understanding Chunking Strategies for LLM Application
Chunking strategies in LLM (Large Language Model) applications refer to the method of splitting large text data into smaller, logical segments for efficient processing. Since LLMs have token limitations, breaking down extensive documents into smaller chunks enables the model to process information without losing context. Common chunking techniques include fixed-length chunking, semantic chunking, and overlapping chunking. Fixed-length chunking splits text based on word count, while semantic chunking divides content by meaning or context, ensuring better coherence. Overlapping chunking helps maintain context across segments by including a portion of the previous chunk in the next. These strategies enhance the model’s ability to generate more accurate and contextually relevant outputs in applications like document summarization, chatbots, and knowledge extraction. Implementing the right chunking approach improves performance, reduces errors, and enables LLMs to handle large datasets effectively.
Why We Need ‘Chunks’ in Language Processing
In language processing, breaking down large text into smaller ‘chunks’ is essential to enhance the efficiency and accuracy of AI models like LLMs (Large Language Models). Most LLMs have token limits, restricting the amount of text they can process at once. Without chunking, lengthy documents or conversations would exceed these limits, leading to incomplete or inaccurate outputs.
Chunks allow LLMs to process text in smaller, more manageable segments while preserving context. This method improves the model’s ability to generate coherent responses and extract key information. Chunking also enhances context retention by dividing text logically, especially when using semantic chunking, which splits content based on meaning rather than arbitrary length.
Additionally, overlapping chunks help maintain continuity between segments, ensuring no critical information is lost during processing. This technique is particularly valuable in applications like document summarization, chatbots, and knowledge-based search systems, where accuracy and contextual understanding are crucial.
By implementing chunking strategies, businesses can optimize language models for large-scale data processing, resulting in faster, more reliable AI solutions that deliver high-quality outputs without compromising information integrity.
How to Choose the Right Chunking Strategy for LLM Application
Selecting the right chunking strategy for LLM applications is key to accurate data processing, context retention, and performance. Choose chunking methods based on text nature, model capabilities, and use case needs. Here’s how to find the best fit:
1. Understand Your Application Needs
Start by identifying the purpose of your LLM application. Whether you’re building chatbots, document summarization tools, or knowledge-based search systems, the type of text processing will determine the chunking method. Applications requiring detailed contextual understanding, such as customer service chatbots, benefit from semantic chunking, while fixed-length chunking works well for uniform data like product descriptions.
2. Analyze Text Structure and Complexity
Evaluate the structure and complexity of your data. If your text consists of simple, uniform content, fixed-length chunking based on word or token count is suitable. However, for complex or technical documents, semantic chunking is more effective, as it preserves the meaning by splitting text based on paragraphs, sentences, or topics rather than arbitrary word counts.
3. Choose Between Fixed-Length and Semantic Chunking
- Fixed-Length Chunking: Splits text into equal-sized parts, making it easier to implement and faster to process. This method is ideal for applications where text structure is consistent, such as product catalogs or news articles.
- Semantic Chunking: Breaks text based on contextual meaning, ensuring that each chunk contains a complete thought or idea. This strategy works best for research papers, legal documents, and customer conversations.
4. Implement Overlapping Chunks for Context Retention
For applications like chatbots or document summarization, where context flow is critical, overlapping chunking helps maintain continuity. This technique involves including a portion of the previous chunk in the next, reducing the risk of losing context between segments.
5. Evaluate Chunk Size
Chunk size plays a significant role in performance. Large chunks may lead to context loss, while smaller chunks improve accuracy but increase processing time. Test different chunk sizes to find the right balance based on your model’s token limit and processing speed.
6. Metadata Tagging for Better Context Management
Add metadata like document titles, timestamps, or section headings to each chunk to help the model understand the context better. This approach improves search accuracy and content summarization, especially in enterprise applications.
7. Test and Optimize
Finally, test different chunking strategies on sample data. Analyze the model’s performance in terms of accuracy, speed, and contextual relevance. Continuously optimize the chunking method based on feedback and results.
Architectural Approaches for Chunking
Chunking is vital in LLM applications to optimize text processing and performance. Architectural approaches vary based on data complexity, model needs, and use case goals. Here are the key methods:
1. Fixed-Length Chunking
This approach splits text into predefined lengths based on word count, token count, or character count. It is simple, fast, and suitable for applications where text follows a consistent structure, such as product descriptions or news articles. However, this method may cut off important information if the chunk size is not carefully selected.
2. Semantic Chunking
Semantic chunking divides text based on natural language structure, such as sentences, paragraphs, or topic-based sections. It ensures that each chunk contains a meaningful unit of information, improving contextual understanding. This approach is ideal for research papers, legal documents, and customer support conversations where coherence is critical.
3. Overlapping Chunking
Overlapping chunking enhances context retention by including a small portion of the previous chunk in the next one. This method helps maintain continuity in applications like document summarization or chatbots, where understanding relationships between sentences is essential.
4. Adaptive Chunking
Adaptive chunking dynamically adjusts chunk sizes based on the content’s complexity and structure. It uses AI algorithms to detect sentence boundaries, topics, or context shifts. This advanced approach is highly effective for knowledge-based search systems and multi-topic documents.
Considerations of Chunking Strategy for LLM Applications
Implementing a chunking strategy in LLM applications demands careful planning to optimize performance, accuracy, and context retention. The right approach enhances information processing, response relevance, and data coherence. Here are key design considerations:
1. Text Type and Complexity
Understanding the nature of the text is essential. Structured content like product descriptions or news articles can be processed using fixed-length chunking, while technical documents, legal papers, or conversational data require semantic chunking to maintain meaning. Complex, multi-topic documents benefit more from adaptive chunking methods.
2. Context Preservation
Preserving context between chunks is critical to ensure the model generates consistent responses. Techniques like overlapping chunking, where a small portion of the previous chunk is included in the next, help maintain the flow of information in applications like chatbots or knowledge extraction systems.
3. Chunk Size Selection
Chunk size directly impacts both performance and accuracy. Larger chunks improve processing speed but may cause context loss, while smaller chunks enhance context understanding but increase computational overhead. The ideal chunk size should balance efficiency and information preservation based on the model’s token limits and application goals.
4. Data Structure
Well-structured content with clear section breaks is easier to segment using semantic chunking. However, unstructured content requires more advanced adaptive chunking methods that can dynamically detect context boundaries using NLP algorithms.
5. Metadata Inclusion
Adding metadata like section headers, timestamps, or content tags helps the model understand the context of each chunk. This technique enhances performance in applications like document summarization and knowledge retrieval systems.
6. Performance Testing
Test different chunking strategies on sample datasets to measure performance in terms of accuracy, speed, and contextual coherence. Continuous testing and iteration are necessary to optimize chunking methods for specific use cases.
Implementing Chunking Strategies for LLM Application Step-by-Step Guide
Chunking strategies enhance LLM performance by dividing large datasets into smaller segments, ensuring seamless processing, context retention, and quality output. This guide outlines the technical implementation process.
1. Data Preprocessing
The first step involves cleaning and preparing the input data. Preprocessing ensures that the text is free from unnecessary elements that could affect chunking performance.
- Tokenization: Split text into sentences or words using NLP libraries like spaCy or NLTK.
- Noise Removal: Eliminate HTML tags, special characters, and irrelevant content.
- Text Normalization: Convert text to lowercase and remove stopwords if necessary.
2. Chunking Strategy Selection
Select the chunking approach based on the text type and application requirements:
- Fixed-Length Chunking: Divide text into equal-sized chunks (e.g., 512 tokens). Suitable for structured and uniform text.
- Semantic Chunking: Use NLP techniques to segment text by paragraphs, sentences, or meaning-based sections. Ideal for unstructured or multi-topic content.
- Overlapping Chunking: Apply this technique to maintain context by including a portion of the previous chunk in the next.
3. Chunk Size Calculation
Determine the optimal chunk size based on the model’s token limit and text complexity.
- Calculate the model’s maximum token limit (e.g., GPT models allow up to 4,096 tokens).
- Use dynamic chunking to adjust chunk size based on content density, especially for technical documents.
4. Chunk Boundary Detection
For semantic chunking, implement algorithms to identify natural text boundaries:
- Use Sentence Boundary Detection (SBD) to split text into sentences.
- Apply Named Entity Recognition (NER) to segment text by topics or named entities.
- Detect section headings or HTML tags in structured documents.
5. Overlapping Context Implementation
Implement overlapping chunks to improve context flow:
- Define an overlap percentage (e.g., 10–20% of the previous chunk).
- Concatenate the last few sentences of the current chunk with the next chunk.
6. Metadata Tagging
Assign metadata to each chunk to improve context understanding:
- Include document title, section headers, timestamps, and page numbers.
- Use JSON or XML formats to store metadata alongside the chunked text.
7. Chunk Indexing
Create an index to keep track of chunk positions and relationships:
- Store chunk IDs, start and end tokens, and metadata references in a relational database or NoSQL datastore.
- Implement indexing for efficient retrieval in retrieval-augmented generation (RAG) pipelines.
8. Validation and Quality Check
Run the chunking pipeline on sample text datasets and evaluate:
- Context Retention Score: Check how well the model preserves meaning across chunks.
- Chunk Coverage Rate: Ensure all text portions are processed without overlaps or omissions.
- Performance Metrics: Measure processing speed and memory consumption.
9. Optimization and Fine-Tuning
Iterate on chunking strategies based on validation results:
- Adjust chunk size and overlap percentage for better context retention.
- Use adaptive chunking techniques that dynamically modify chunk sizes based on content complexity.
10. Integration with LLM Pipeline
Finally, integrate the chunking module into the main LLM pipeline:
- Use APIs like Hugging Face Transformers or OpenAI API to send chunked data to the model.
- Merge the model’s output chunks into a unified response using post-processing algorithms.
Advanced Chunking Techniques for LLM Applications
Advanced chunking techniques use AI, dynamic processing, and adaptive strategies to enhance context retention, accuracy, and performance in LLM applications, especially for complex datasets in healthcare, legal, finance, and customer support.
1. Adaptive Dynamic Chunking
Adaptive dynamic chunking automatically adjusts chunk sizes based on content complexity and context density. Instead of fixed token limits, this technique uses NLP models to detect structural elements like headings, sentence complexity, or semantic shifts.
How It Works:
- Utilize sentence embeddings from libraries like spaCy or Hugging Face to calculate content similarity between consecutive sentences.
- When a significant semantic shift is detected, create a new chunk boundary.
- Apply hierarchical chunking, where large sections are divided into smaller semantic units based on complexity.
Use Case: Multi-topic knowledge bases or research papers.
2. Recursive Chunking
Recursive chunking breaks down long-form documents into smaller, nested chunks in multiple iterations. This technique helps maintain context across hierarchical data structures like contracts, technical manuals, or scientific documents.
How It Works:
- First, divide the document into broad sections.
- Further split each section into paragraphs and then into sentences.
- Process each level of the hierarchy independently, while passing contextual information from parent chunks to child chunks.
Use Case: Legal document summarization or technical specification analysis.
3. Context-Aware Overlapping Chunking
Unlike fixed-length overlapping, context-aware overlapping dynamically determines overlap size based on the importance of the last sentences in a chunk. This technique uses attention-based models to assign importance scores to sentences.
How It Works:
- Use BERT or GPT-based models to generate attention weights for each sentence.
- Include high-weighted sentences from the previous chunk into the next chunk.
- This ensures that critical contextual information is preserved without excessive redundancy.
Use Case: Conversational AI or FAQ-based applications.
4. Entity-Based Chunking
Entity-based chunking segments text based on the presence of named entities like persons, organizations, dates, and locations. This technique helps isolate contextually related information for improved knowledge extraction.
How It Works:
- Use NER (Named Entity Recognition) models to identify entities in the text.
- Group consecutive sentences containing the same entities into a single chunk.
- Link related chunks based on entity co-occurrence.
Use Case: Knowledge graph construction or customer support ticket analysis.
5. Hybrid Chunking
Hybrid chunking combines multiple chunking techniques within a single pipeline. For example, semantic chunking can be applied first, followed by overlapping chunking for finer segmentation.
How It Works:
- Apply semantic chunking to divide content into broad sections.
- Use adaptive dynamic chunking for smaller sub-sections.
- Add context-aware overlapping to preserve critical context between chunks.
Use Case: Document summarization and retrieval-augmented generation (RAG) systems.
6. Graph-Based Chunking
Graph-based chunking models text as a semantic graph, where nodes represent sentences or paragraphs, and edges indicate semantic similarity. This method is ideal for documents with complex cross-references.
How It Works:
- Construct a similarity graph using sentence embeddings.
- Identify sub-graphs of highly interconnected nodes.
- Treat each sub-graph as an independent chunk.
Use Case: Knowledge base applications or multi-topic customer queries.
Real-World Use Cases and illustrative examples
Chunking strategies boost LLM efficiency by dividing large data into smaller, context-rich segments, improving processing, context retention, and performance. Here are key real-world use cases.
1. Document Summarization in Legal Services
Use Case: Legal contracts and case documents often span hundreds of pages, making it difficult to extract key information quickly. Chunking helps segment these documents into manageable sections based on legal clauses or topics.
Illustrative Example:
A legal tech company uses recursive chunking to divide contracts into hierarchical sections such as preamble, obligations, payment terms, and termination clauses. Each section is processed independently to generate concise summaries, while entity-based chunking extracts parties, dates, and financial amounts for cross-referencing.
Outcome: This approach significantly improves the speed of contract review and enhances the accuracy of legal document summarization.
2. Knowledge Base Search in Customer Support
Use Case: Customer support platforms use LLM applications to retrieve relevant knowledge base articles in response to user queries.
Without proper chunking, the model might miss key information or return incomplete results.
Illustrative Example:
A SaaS provider implements semantic chunking on its product documentation, dividing content by feature descriptions and troubleshooting steps. Each chunk is indexed along with metadata tags like feature name and version. When users ask for help, the model retrieves the most relevant chunks, improving search accuracy.
Outcome: Faster issue resolution and better user experience in self-service portals.
3. Medical Research Analysis in Healthcare
Use Case: Medical research papers and clinical trial reports contain dense scientific information that requires precise extraction for analysis.
Illustrative Example:
A healthcare AI platform uses adaptive dynamic chunking to split clinical trial reports into sections based on abstract, methodology, results, and conclusion. The model processes each section independently, prioritizing high-density paragraphs with greater overlap to preserve context. Named Entity Recognition (NER) identifies key medical terms and drug names.
Outcome: Faster data extraction and improved knowledge synthesis for medical research applications.
4. Question Answering Systems in E-Commerce
Use Case: E-commerce websites use LLM-powered chatbots to answer product-related customer queries. The responses must be accurate and contextually relevant.
Illustrative Example:
An e-commerce platform applies overlapping chunking to product descriptions and customer reviews. Each chunk includes product specifications, usage instructions, and FAQs, with a 20% overlap between adjacent chunks to ensure consistent answers.
Outcome: Improved accuracy in answering customer queries and higher customer satisfaction rates.
5. Document Retrieval in Financial Services
Use Case: Financial institutions process large volumes of regulatory documents and client agreements that need efficient retrieval and analysis.
Illustrative Example:
A financial services firm uses graph-based chunking to model regulatory documents as semantic graphs. Nodes represent paragraphs, while edges indicate cross-references between legal sections. Queries about specific clauses automatically retrieve the most relevant interconnected chunks.
Outcome: Faster document search and compliance verification with minimal manual intervention.
6. Content Moderation in Social Media Platforms
Use Case: Social media platforms monitor user-generated content to detect harmful language, misinformation, or spam.
Illustrative Example:
A content moderation system applies entity-based chunking to break down social media posts into smaller segments based on user mentions, hashtags, and URLs. Each chunk is analyzed independently for policy violations, while related chunks are linked to preserve context.
Outcome: More accurate content filtering and reduced false positives in moderation pipelines.
How GlobalNodes can help you
GlobalNodes empowers businesses to optimize their LLM applications with advanced chunking strategies and AI-driven solutions. Our expertise in semantic chunking, adaptive dynamic chunking, and graph-based chunking ensures precise data segmentation, improving context retention and model accuracy. Whether you’re building conversational AI, document summarization systems, or knowledge extraction pipelines, GlobalNodes customizes solutions to fit your business needs. With seamless integration and scalable architectures, we help you unlock the full potential of your AI applications, driving faster insights and better decision-making.
Partner with GlobalNodes to revolutionize your AI-powered workflows.